Featured
Jun 9, 2026
Introducing Linx AI Access Control: Real-Time Governance for AI Agent Actions

Linx was recently recognized in two separate Gartner® reports: the Hype Cycle™ for Digital Identity, 2026 (July, 2026) and Infuse Agentic AI to Enhance Your IGA (June, 2026). Here's what excites me more than the mention itself: what it validates about where the market is heading, and what it means for the future of security as we see it.
For years, identity access management felt static. You'd implement your IAM platform, set up policies, and then spend the next five years asking humans to review, approve, and audit access decisions. It was reactive. It was slow. And it was broken for the speed at which modern work actually happens.
Then AI agents changed the game.
Not in the "replace your identity team" way people feared. And not as a bolt-on feature to legacy IAM either. But as something fundamentally different: autonomous agents that understand your organization's context and make intelligent access decisions - for humans and other agents.
Think of it this way: traditional IAM asks "does this policy allow this access?" Agentic access control asks "what does this entity, person or agent, actually need, given their role, project, peer group, and what they're trying to accomplish right now?"
But here's the problem today: as your organization deploys more AI agents (for customer service, automation, data processing, orchestration), those agents need access too. They need to authenticate. They need permissions. They need governance. And they need it at machine speed, not human speed.
The organizations building for 2027 aren't just managing access for people. They're managing access for agents - and that requires a completely different architecture than traditional identity management was designed for.
That shift from policy-driven to context-driven, from reactive to autonomous, from human-only to human-and-agent access control - that's what's reshaping how leading organizations think about access.
Recent industry recognition acknowledges something we've been building toward: a new category of platforms that combine modern IGA capabilities with autonomous AI agents. The distinction matters: these aren't identity platforms with a chatbot feature. They're platforms where agents actively make contextual decisions about access, learn from your organization, and operate with minimal human intervention.
Linx is one of the few platforms architected this way from the ground up. We don't layer AI on top of identity policy. We've built identity and autonomous agents together - where agents are core to how the platform works, not an afterthought. That’s what it means to be AI-native.
Our customers have been telling us this for over a year: they want autonomous agents making smarter access decisions in real time, at scale, without creating review bottlenecks. They want agents that learn their organization's culture and dynamics, not AI that requires constant human hand-holding.
We believe that when Gartner identified agentic access control as the future - separate from traditional IGA - it validated what we've been hearing from customers in the trenches and what we've been building.
Look, we're proud of the recognition - genuinely. But the real story isn't about Linx being named. It's about your organization transforming how it approaches access control through autonomous agents.
This is bigger than identity access management. It's about reimagining what access control means when you have agents that can reason about context, learn organizational patterns, and make decisions autonomously.
The organizations at the forefront, and the ones recognized by Gartner, are the ones that have already figured this out:
Our customers - from healthcare to fintech to large enterprises - are already running on this principle. They're not asking us to add more features to identity management. They're asking us to let autonomous agents handle access control for both humans and machines while their teams focus on strategy, exceptions, and governance oversight.
And the smartest ones are thinking ahead: "What happens when we have 50 LLM agents running in production? How do we grant them access securely? How do we audit what they're doing? How do we revoke permissions when a project ends?" Those are the conversations that separate platform builders from identity vendors.
If you're running identity access today, ask yourself three questions:
In our opinion, Gartner's research isn't predicting the future anymore - it's documenting what forward-thinking organizations are already doing.
Here's what I tell our team every day: the win isn't being first. It's being useful.
We built agentic AI into the fabric of Linx from the start because it’s what our customers needed. We made our agents contextual because policy-only doesn't solve the real problem. And we made them native because grafting AI onto legacy systems creates more complexity, not less.
But we're not the only ones moving this direction - and that's a good thing. The more platforms that embed intelligent, context-aware access decisions, the faster the industry shifts away from "review every request" and toward "empower teams with intelligence."
For us: we're doubling down on what customers are telling us works: autonomous agents that understand organizational context, intelligent access decisions at scale for humans and other agents, and continuous improvement through learning. Not as an add-on to identity. As the core of how access control works in an AI-native world.
For you: if you haven't started thinking about agentic access control, now's the time. Not because Gartner said so, but because your organization's work has already moved beyond what traditional identity management was designed for. You're deploying AI agents. You're building autonomous workflows. You're connecting systems at machine speed. Your access control system needs to keep up.
The question isn't "how do we automate identity policies?" It's "how do we let autonomous agents make access decisions intelligently for both humans and machines, using identity as one input, while our teams focus on strategy, exceptions, and security oversight?"
We're here to help if you want to talk about what agentic access control looks like in practice - not as IGA with AI tacked on, but as a fundamentally different platform built for a world where both humans and agents need secure, intelligent, auditable access. Or if you want to hear directly from customers who've already made the shift - they're managing access for their AI systems today, and those stories show you what becomes possible when you move from identity-first to agent-first thinking.
P.S. If you have a Gartner subscription and want to dig into the full research on where identity is heading, check out the Gartner Hype Cycle for Digital Identity, 2026 and the Gartner report titled Infuse Agentic AI to Enhance Your IGA. And if you want to hear from customers doing this today - how they've accelerated access decisions while improving security - let's talk.
GARTNER and HYPE CYCLE are trademarks of Gartner, Inc. and/or its affiliates. Gartner does not endorse any company, vendor, product or service depicted in its publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner publications consist of the opinions of Gartner’s business and technology insights organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this publication, including any warranties of merchantability or fitness for a particular purpose.
An AI agent can hold more standing access than any employee in your company and exercise all of it in seconds, without pausing to think. It authenticates with real credentials, reads and writes across dozens of systems, and often acts on borrowed identities that make it hard to say who actually did what.
That's the problem AI access control solves: not whether agents get access, but what they're allowed to do once they have it. And the timing is not theoretical. Gartner predicts that 40% of enterprise applications will embed task-specific AI agents by the end of 2026, up from less than 5% in 2025. Every one of those agents authenticates, authorizes, and acts with a real identity blast radius.
This guide covers what AI access control is, why existing identity and access management fails to govern agents, what a mature framework includes, and how to implement it across your organization.
AI access control is the discipline of governing what AI agents and autonomous systems can access, invoke, and modify inside enterprise environments, including the policies and real-time enforcement that determine which systems an agent can reach, which actions it can perform, and under what conditions access is granted or denied.
Note the distinction: this is not about using AI to improve traditional access management (AI-powered access reviews, AI-driven role recommendations). As identity and security teams increasingly use the term, AI access control means controlling the access of the AI agents themselves. It is the foundation of a broader AI access governance strategy.
The reason the category is emerging now is simple: AI agents are identities. They hold credentials, authenticate to systems, and take actions that carry consequences, but most organizations lack the controls to govern them. According to IBM's 2025 Cost of a Data Breach Report, 97% of organizations that suffered an AI-related breach reported lacking proper AI access controls. That signals a systemic gap, not an edge case.
An AI agent is not a feature inside an application. It authenticates with credentials (API keys, OAuth tokens, service accounts), holds entitlements, and executes actions across an access footprint that can span dozens of systems.
Traditional IAM assumes the entity requesting access is a human. Joiner-mover-leaver processes, access certifications, and role-based access control (RBAC) all assume identities change at a pace a human reviewer can keep up with. Agents break that assumption: they are created programmatically, can replicate without lifecycle controls, and frequently operate on shared or delegated credentials — so the identity that acted is often not the agent's own. That attribution gap is what makes agentic access uniquely hard to govern. A Cloud Security Alliance survey found only 18% of organizations are highly confident their current identity systems can handle agent identities.
Standing privileges are already one of the largest sources of human identity risk: dormant accounts, admin sprawl, inherited permissions. With agents the problem compounds, because they operate continuously and can persist long after the workflow they were built for has ended.
Consider a support agent provisioned on a shared service account that can both read customer PII and write to a production database — spun up outside security's view, and still live three months after its task was retired. When a human accumulates that access, risk grows gradually. When an agent does, it can exercise every permission it holds in seconds. The blast radius of a single over-permissioned agent can exceed that of any individual human user.
Quarterly access reviews and static roles were designed for slow-changing access that a human can meaningfully evaluate. Agents can be created, modified, and retired in hours, and may touch different systems on every execution. A quarterly certification can't keep pace, and a static RBAC model can't capture context-dependent agent access. Governing agents requires an approach that operates continuously and enforces at the point of action, not months later.
A mature AI access control framework covers six capabilities. Each addresses a different dimension of the problem, and all are needed to govern agents at scale.
You cannot govern what you cannot see. Discover every agent in your environment, map the credentials it holds, and identify what it can reach — including shadow agents spun up outside security's view. This matters more than it sounds: a 2026 CSA survey found 82% of enterprises already have unknown AI agents operating in their environments.
An agent should have access only to the systems and data a specific task requires, at the minimum permission level. That means moving away from broad, persistent agent credentials toward scoped, purpose-specific access profiles.
Controlling which systems an agent can reach isn't enough, and neither is controlling which tool it calls. A single tool can be harmless or catastrophic depending on its arguments: execute_sql with a SELECT is routine; the same tool with DROP TABLE is not. Real least privilege reaches the parameter level — allowed values, table and scope allowlists, row limits, response redaction — not just the tool name. In practice, a well-scoped policy looks like this: allow the query tool, permit only SELECT statements, restrict it to two named tables, and cap the response at 100 rows, all evaluated on the single tool call before it runs. An inline MCP gateway is the natural enforcement point here, because it's the only layer that sees the full tool call, arguments included, before it executes.
Control that operates after the fact, such as through logs or periodic review, is too slow for agents acting at machine speed. This is the function of an MCP gateway: a real-time layer between AI platforms and the applications they reach through the Model Context Protocol. When an agent makes a tool call, the gateway evaluates it against policy, approves or blocks it, and logs the decision, all before it reaches the target system. Inline enforcement is what makes AI access control operational rather than aspirational.
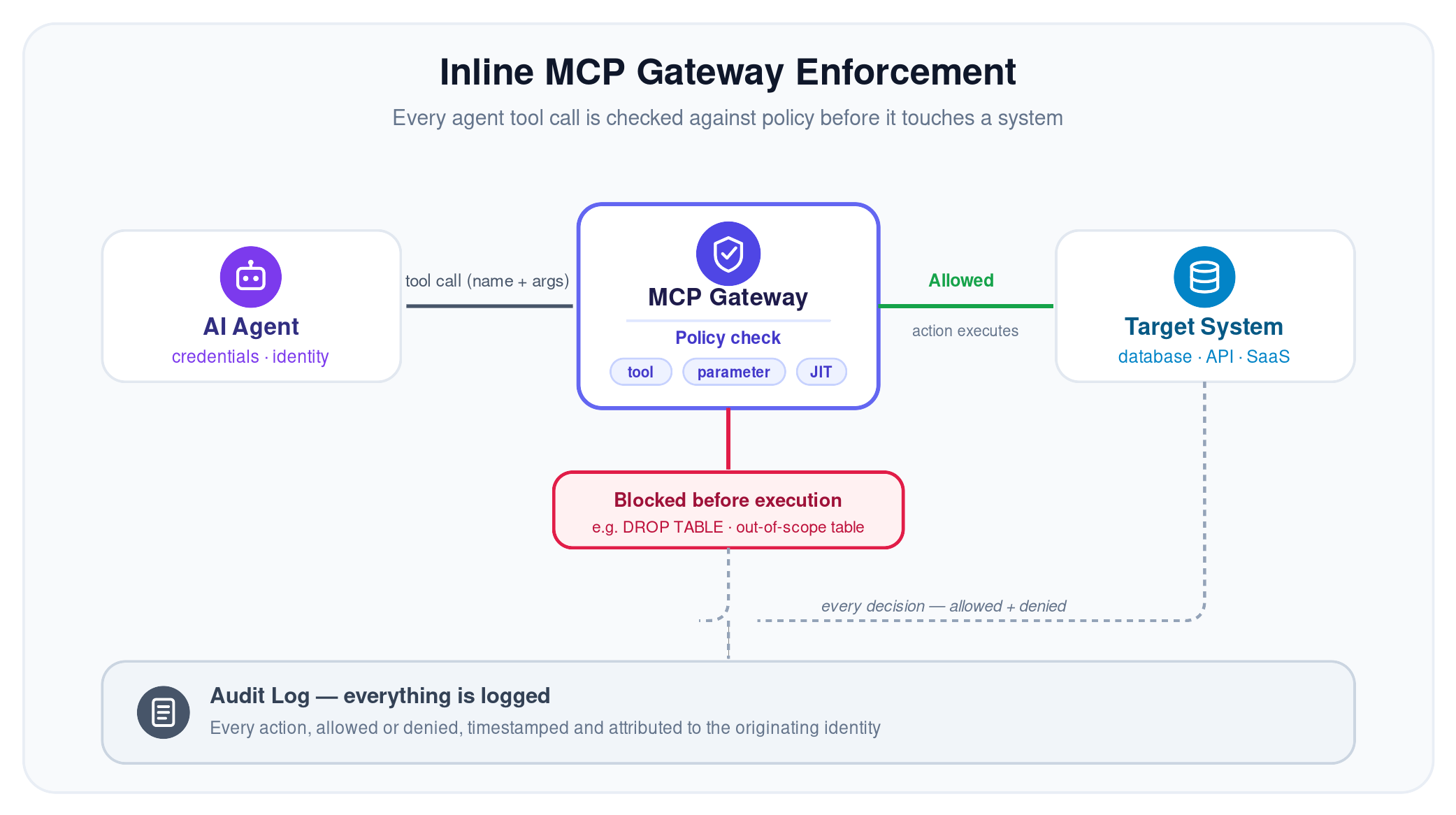
JIT access replaces standing agent privileges with time-bound, scoped access granted per task and revoked automatically when the task completes. If an agent needs to write to production for one workflow, JIT grants it for the duration and removes it immediately after, thus shrinking the window of exposure if the agent is compromised.
Every agent action — approved or denied — should be captured, timestamped, and traceable to the identity behind it, human or non-human. Comprehensive audit trails enable incident investigation and provide the evidence needed for SOC 2, ISO 27001, and emerging AI-specific regulations.
The through-line across every practice below is one idea: agents cannot be governed in a silo. They act on behalf of humans, use service-account credentials, and touch the same systems every other identity does. Governing them separately gives you an incomplete view of risk.
AI access control is an extension of your identity governance and ISPM into a new layer. The same access profile logic, policy framework, and certification workflows that govern humans should extend to agents. A parallel agent-only stack produces fragmented visibility and inconsistent enforcement.
Agents act on behalf of humans, use service account credentials, and touch the same systems that human and non-human identities access. Therefore, effective AI access governance requires a unified identity model where every entity (human, non-human, and agent) is visible, governable, and subject to consistent policy. This is what an identity graph enables — correlating every identity, entitlement, and relationship so policy decisions reflect full context.
MCP, API keys, OAuth tokens, service accounts, and cloud IAM roles each grant agents a path into enterprise systems. MCP is fast becoming the standard for agent-to-tool communication, which makes gateway enforcement critical, but a complete strategy covers every credential surface, not just the newest protocol.
Begin with agents that carry the most risk: write access to production, access to sensitive data, permissions in regulated environments. Establish AI access controls for those workflows first, demonstrate value, and then expand coverage systematically. Trying to govern every agent at once leads to stalled deployments and governance fatigue.
The following practices reflect what mature AI access governance programs are converging on.
Treat every agent as an identity with a lifecycle — onboard, review, and decommission it like any human or non-human identity.
Default to deny — start with no access; grant only what each task justifies.
Enforce policy inline, at the point of action — not reconstructed from logs later.
Unify agent governance with your existing identity program — one platform, one policy framework.
Apply tool- and parameter-level granularity — control the arguments, not just the tool.
Audit every action, including denials — denials reveal misconfigurations and abuse.
AI access control is not a future problem. Agents are already operating inside enterprise systems at scale, and the gap between deployment velocity and governance maturity is widening.
The core principle hasn't changed: see every identity, enforce least privilege, keep an auditable record of every action. What changes with agents is the speed, the scale, and the enforcement mechanism. Policy has to operate inline, granularity has to reach the tool call, and governance has to span humans, non-human identities, and agents on one platform. That is the approach organizations take with Linx, which extends unified agentic identity governance and real-time MCP gateway enforcement into the same platform that already governs human and non-human identities.
Ready to see what AI access control looks like in practice? Get a demo and watch every agent action get governed in real time, without slowing AI adoption.
AI access control is the set of policies, processes, and enforcement mechanisms that govern what AI agents can access, invoke, and modify inside enterprise environments. It covers discovery, least privilege, inline enforcement, just-in-time access, and continuous monitoring for autonomous AI systems.
Traditional IAM was built for human users who request access through defined processes and whose entitlements change at a pace periodic reviews can manage, while AI access control addresses entities created programmatically that operate at machine speed and act continuously across systems. It requires real-time enforcement, tool- and parameter-level granularity, and lifecycle management for agent identities — where traditional IAM relies on periodic certification.
Yes, AI agents need their own identities. Agents authenticate with credentials, hold permissions, and take consequential actions. They should be treated as identities with defined access profiles, lifecycle governance, and audit trails — just like human users and non-human identities such as service accounts and API keys.
An MCP gateway is an inline enforcement layer between AI platforms and the applications they reach through the Model Context Protocol. It inspects every tool call an agent makes, evaluates it against policy, and approves or blocks the action before it executes — providing real-time control, tool-level granularity, and full audit logging for agentic workflows.
Yes, zero trust applies to AI agents. Never trust, always verify, enforce least privilege — applied to agents, this means authenticating on every request, granting only the minimum access each task needs, and logging every action to an attributable identity. AI access control is how organizations operationalize Zero Trust for the agentic layer.
AI governance is broader than AI access control and includes model safety, bias mitigation, data governance, regulatory compliance. AI access control is the identity and access dimension of that challenge: controlling what agents can access and do inside enterprise systems. Most organizations start with AI access control because access is the most immediate and measurable risk.
Enforcing least privilege for agents requires three things: right-sized access profiles that match the agent's actual task (not broad, inherited credentials), tool-level granularity distinguishing read/write/admin actions, and just-in-time access granted per workflow and revoked automatically. Default to deny, and grant only when the workflow justifies it.
When considering AI access control tools, you should look for inline enforcement at the tool-call level (not just post-hoc monitoring), tool- and parameter-level granularity, unified governance across human, non-human, and agent identities in a single platform, just-in-time access for agent workflows, full audit logging with attribution, and integration with your existing identity governance and ISPM.
Securing AI agents starts with treating them as identities: discover every agent in your environment, assign each a scoped identity, enforce access policy in real time through inline controls like an MCP gateway, and keep complete audit trails of every action. Integrate this into your broader identity security program rather than running it as a separate initiative.
Treat every agent as an identity with a full lifecycle, default to deny, enforce policy inline at the point of action, unify agent governance with your existing identity program, apply tool- and parameter-level granularity, and audit every action including denials. Start with high-risk workflows and scale systematically.
User access reviews, also called access certifications, remain one of the most important identity governance controls organizations perform. They help security teams verify that users have the appropriate access to systems and data, enforce least privilege, and satisfy compliance requirements like SOX, SOC 2, HIPAA, GDPR, and ISO 27001. While the objective of access certifications hasn't changed, the environments they're designed to protect have.
Organizations now manage significantly more identities, applications, and permissions than they did just a few years ago. Employees use hundreds of SaaS applications, cloud adoption continues to grow, contractors regularly enter and leave the business, and non-human identities (NHIs) and AI agents are becoming part of everyday operations. As identity environments become more complex, traditional access certification processes become increasingly difficult to manage.
Our Complete Guide to Modern User Access Reviews explores why organizations struggle with access certifications today, what a modern review program should look like, and how automation and AI are helping identity teams improve security while reducing manual effort.
The biggest challenge facing access certifications isn't the review itself. It's the volume and complexity of identities that now require governance.
A typical organization is responsible for reviewing access across:
Every new application introduces additional permissions. Every employee who changes roles creates new access decisions. Every contractor, service account, and AI agent expands the organization's attack surface. Without complete visibility into those identities and permissions, security teams spend more time gathering information than reviewing access. This is why so many organizations are prioritizing projects to modernize and automate user access reviews.
Most organizations encounter the same challenges when running user access reviews. As identity environments grow, these issues become more difficult to overcome without automation.
These challenges don't just slow down access certifications. They also increase identity risk by delaying remediation and making it more difficult to demonstrate compliance.
Modern user access reviews go beyond periodic certification campaigns. Instead of relying on manual processes and disconnected tools, organizations are building review programs that improve visibility, automate repetitive work, and help reviewers make more informed decisions.
Every effective access certification program includes six core stages:
Each stage plays an important role. Visibility ensures organizations understand who has access before reviews begin. Context helps reviewers make informed decisions instead of relying on guesswork. Automated remediation shortens the time between identifying unnecessary access and removing it, while centralized reporting simplifies audit preparation.
Download The Complete Guide to Modern User Access Reviews to explore each stage in detail and learn how modern organizations transform and automate user access reviews.
To automate user access reviews is to remove much of the manual work that slows the process down. Rather than exporting data from multiple systems, assigning reviews through spreadsheets, and manually tracking remediation, identity governance platforms automate these tasks from beginning to end.
When organizations automate user access reviews they:
By reducing manual effort, security teams can spend more time evaluating identity risk and less time managing administrative tasks.
AI is changing every stage of the user access review process. Instead of asking reviewers to evaluate every permission equally, AI helps security teams identify where risk actually exists. Reviewers receive recommendations based on identity context, access history, peer comparisons, and risk signals, allowing them to spend more time validating high-risk access and less time reviewing routine permissions.
AI also helps reduce one of the biggest challenges in access certifications: reviewer fatigue. Managers no longer need to sift through hundreds of permissions without context. Instead, they can focus on the access decisions that require attention while routine reviews become faster and more consistent.
AI can support user access reviews by:
As organizations continue adopting AI throughout the business, identity governance must also expand to govern AI agents alongside human users, contractors, and non-human identities. Modern access certifications are becoming an important part of securing every identity interacting with enterprise systems.
For many organizations, user access reviews are still treated as quarterly or annual compliance exercises. While those reviews remain important, they only provide a snapshot of access at a single point in time.
Identity environments don't wait for the next review cycle. Employees change roles, new applications are deployed, contractors leave projects, and permissions accumulate every day. Waiting months to identify unnecessary access creates unnecessary risk.
That's why many organizations are moving toward continuous identity governance. Rather than relying solely on scheduled certification campaigns, they continuously monitor identities, permissions, and access changes throughout the year.
A continuous approach helps organizations:
Access certifications remain a foundational control, but they become significantly more effective when they're part of a broader identity governance strategy instead of a standalone compliance activity.
Every organization approaches user access reviews differently, but the most successful programs share several characteristics. Instead of focusing only on completing review campaigns, they build repeatable processes that improve security over time.
The highest-impact improvements include:
Organizations that follow these practices spend less time preparing review campaigns and more time improving their overall identity security posture.
When you automate user access reviews, you do not have to overhaul your entire identity governance program overnight. Most organizations start by identifying the parts of the review process that consume the most manual effort and introducing automation incrementally.
Here's how to approach it:
Automation starts with visibility. Before you can automate user access reviews, your identity governance platform needs to pull access data from every system in scope: SaaS applications, cloud environments, Active Directory, HR systems, and any other source that assigns permissions. The more complete your identity inventory, the less manual preparation your team needs to do before each review cycle.
Access data from different systems rarely arrives in a consistent format. Automated platforms normalize data from disparate sources into a unified identity model, making it possible to compare permissions across applications, link identities to their owners, and identify orphaned accounts or excessive access before reviewers ever open a campaign.
Rather than manually building review campaigns from scratch each cycle, automated platforms let you define review scope in advance — which applications, roles, or identity types to include — and set triggers based on risk signals, regulatory schedules, or identity events like role changes and contractor offboarding. This ensures reviews run consistently without requiring manual coordination every time.
Reviewer fatigue is one of the most persistent problems in access certifications. Automated user access review platforms surface information alongside each access decision: when access was last used, how it compares to peers in the same role, whether a permission is considered high risk, and what business justification was provided when access was originally granted. With that context in place, reviewers can make faster, more informed decisions.
Modern identity governance platforms use AI to analyze access patterns, usage data, and risk signals and pre-populate review decisions for lower-risk permissions. Reviewers can focus their attention on flagged exceptions while routine access is handled consistently and efficiently. This dramatically reduces the number of decisions reviewers need to make manually, without sacrificing accuracy.
Identifying unnecessary access is only valuable if it gets removed. To truly automate user access reviews, you must automate identity risk remediation. Automated remediation closes the loop by triggering access removal directly after a reviewer certifies a revocation decision, without requiring a manual ticket or a separate provisioning workflow. This shortens the window between review and action, reducing identity risk rather than just documenting it.
Audit readiness is a recurring challenge when review decisions, approvals, and remediation actions live in different systems. Automated user access review platforms capture a complete audit trail throughout the review process including who reviewed what, what decision was made, when, and what action was taken. That evidence is available on demand without additional manual effort when compliance reviews or external audits arise.
Linx automates each of these stages within a single identity governance platform. By connecting to your existing identity sources, continuously monitoring access, and surfacing AI-powered recommendations to reviewers, Linx helps security teams run faster, more accurate, automated user access reviews across human users, service accounts, non-human identities, and AI agents.
User access reviews have evolved. The growth of SaaS applications, cloud infrastructure, AI, and non-human identities has made identity governance significantly more complex than it was just a few years ago. Traditional review processes built around spreadsheets and manual approvals are becoming increasingly difficult to scale.
The Complete Guide to Modern User Access Reviews takes a deeper look at each stage of the review lifecycle and explains how organizations can modernize and automate access reviews with AI, automatic remediation, and continuous identity governance.
Inside the guide, you'll learn:
Download the Complete Guide and learn how to automate user access reviews. Discover how to build a faster, smarter, and more effective access certificaiton program.
A user access review (UAR), also called an access certification or entitlement review, is the process of validating that users have the appropriate access to applications, systems, and data. Organizations use user access reviews to enforce least privilege, reduce identity risk, and satisfy compliance requirements.
User access reviews help organizations identify excessive permissions, remove unnecessary access, improve identity governance, and demonstrate compliance with frameworks such as SOX, SOC 2, HIPAA, GDPR, ISO 27001, and PCI DSS.
Most organizations perform quarterly or annual user access reviews based on regulatory requirements and business risk. Many are also choosing to automate user access reviews or adopt continuous identity governance to monitor access changes throughout the year instead of relying only on scheduled review cycles.
The terms “user access review” and “access certification” are often used interchangeably. User access review is the broader practice of validating access, while access certification typically refers to the formal review process required to demonstrate compliance. Both aim to ensure users only have the access they need.
Yes, organizations can automate user access reviews using modern identity governance platforms that automate data collection, reviewer workflows, AI-powered recommendations, remediation, reporting, and audit evidence. Automation reduces manual effort while improving consistency, security, and compliance.
AI can automate user access reviews by helping security teams identify high-risk permissions, prioritize reviews, reduce reviewer fatigue, recommend certification decisions, and surface unusual access patterns that might otherwise go unnoticed.
Identity governance is the process of ensuring users and identities have the right access to the right resources at the right time. It combines access certifications, identity lifecycle management, policy enforcement, automation, and reporting to reduce identity risk and support compliance.
Identity lifecycle management governs user access as employees and contractors join, change roles, or leave an organization. Effective lifecycle management reduces excessive permissions before review campaigns begin, making access certifications more efficient and more accurate.
Continuous identity governance extends access certifications beyond periodic certification campaigns. By continuously monitoring identities, permissions, and access changes, organizations can identify and remediate risk faster while improving security and compliance.
AI agents and NHIs should be governed alongside human identities in user access reviews. Modern user access reviews should use the same access profile logic, policy framework, and certification workflows for human, non-human, and agentic identities. IGA tools and AI access control tools can help with access certifications for all identity types.
Most teams treating MCP security as a transport layer problem will build something that looks secure until an agent calls a privileged tool with no auditable identity behind it, no logged intent, and an access control layer that has no opinion about either. We know because we started there too.
The Model Context Protocol solves a real coordination problem - it gives AI agents a standard interface to invoke tools across systems. What it doesn't solve is the identity and access control problem that comes with it. That gap is where we spent most of our engineering time, and it's where most MCP Gateway implementations are quietly underbuilt.
When a human user calls an API, you have a session, a principal, a token with scopes, and usually an audit trail that ties the action back to a person. When an agent calls a tool via MCP, you have none of that by default.
There's no stable principal attached to the tool call. There's no native intent signal. The protocol doesn't carry why the call is being made, only what is being invoked. And there's no inherent sensitivity rating on the tool itself; your gateway doesn't know whether it's about to execute a read against a low-value dataset or trigger a privileged write against a production secrets store.
Your RBAC rules, your session-based policies, your attribute-based controls, all of them were designed around a model where identity is asserted at the front door. MCP tool calls don't come through the front door.
After working through this problem in production, we landed on three questions that any meaningful MCP access control layer has to answer before allowing execution:
Who is behind this call? Not just which agent, but what identity is driving it - human, service account, or another agent in a chain. This requires resolving the full identity context behind the tool invocation, not just authenticating the MCP client.
Why is this call being made? Intent isn't something MCP carries natively, so you have to derive it. We do this by analyzing the prompt that triggered the agent and the declared mission of the agent itself. A tool call to query a Snowflake table is routine from an analytics agent running a scheduled report. That same agent issuing a write call to drop or modify a table — against a prompt that never mentioned data changes — is exactly the kind of drift that contextual controls are designed to catch.
How sensitive is the tool being invoked? Not all tools carry the same risk. A read-only lookup is not equivalent to a tool that can modify IAM policies or exfiltrate credentials. Your gateway needs a sensitivity model for tools - not just for the identities calling them.
Miss any one of these three and your controls have a gap. Miss all three and you have an authentication theater.
Tools need credentials to do anything useful - API keys, OAuth tokens, service account secrets. In a naive MCP implementation, those credentials are either hardcoded into the tool definition or injected at runtime by the agent. Both create NHI governance problems.
Hardcoded credentials don't rotate, aren't scoped to the calling context, and are invisible to your secrets management layer. Runtime injection by the agent means your gateway never sees the credential - it only sees the tool call result. Neither model gives you control over what's being used, by whom, or under what conditions.
The right model is gateway-mediated credential injection: the gateway resolves what credential the tool needs, fetches it from a secrets store under the calling identity's entitlements, injects it at call time, and never exposes it to the agent layer. This is also where JIT access becomes meaningful in practice. Rather than maintaining standing credentials per tool, you issue time-bound credentials scoped to the specific invocation context - so a compromised agent session doesn't carry persistent access to anything downstream.
This is one of the places where the NHI problem and the MCP security problem are the same problem. If you don't have a governed view of what non-human identities exist, what credentials they hold, and what they're entitled to access, you can't implement this model. You're back to hoping the agent behaves.
Getting authentication working is tractable. The harder problem, and where we spent the most time, was extending our existing permissions model to cover MCP tool calls.
We already had a mature permissions framework built around human and non-human identities: entitlements, access policies, the identity graph that maps relationships between principals and resources. The question was whether we could stretch that model to evaluate tool-level access without rebuilding it from scratch.
The short answer: yes, but it required rethinking what a "resource" means in the context of MCP. A tool isn't a static resource with fixed permissions, it's an action with variable risk depending on the context in which it's invoked and the resources involved. The same tool call can be low-risk in one context and a critical control violation in another.
What we built evaluates all three context signals, identity, intent, tool and resource sensitivity, at call time, against the same policy layer that governs the rest of our identity controls. The MCP Gateway doesn't maintain a separate access control silo; it's an enforcement point within the existing identity graph.
When a tool call arrives at the gateway, here's what happens before execution is allowed:
Every decision is audited. Not just whether the call was allowed or denied, but why, which signals were present, which policy rule evaluated, and what the full identity context was at the time.
The teams that frame MCP security as a routing and authentication problem will ship something. It will handle credential injection, it will proxy tool calls, and it will probably produce some logs. What it won't do is enforce meaningful controls on who can call what under which conditions - and in an enterprise environment running agentic workflows at scale, that gap is where your blast radius lives.
We built the gateway we needed because the identity problem behind MCP isn't a future concern. It's in production now, in every organization that's deployed an AI agent with access to real tools.
If you want to see how contextual AI access control works across your MCP environment, request a demo.

Identiverse has always been one of the best places to understand where the identity market is headed. This year, the conversations felt especially clear: identity teams are being asked to govern more identities, more access, and more risk than ever before.
Across sessions, booth conversations, customer meetings, and hallway discussions, one theme kept coming up. Identity is expanding beyond the workforce. It now includes non-human identities, AI agents, autonomous workflows, and new access paths that many organizations are still learning how to control.
For Linx, Identiverse was an opportunity to listen, learn, and share what we have been building. We talked with identity leaders about modern IGA, AI governance, MCP, non-human identity security, user access reviews, and the future of real-time identity governance.
Here are the biggest themes we heard.
For years, identity governance centered around employees, contractors, partners, and privileged users. That work is still critical, but the identity landscape has changed.
Organizations are now managing service accounts, API keys, machine identities, cloud roles, AI agents, and autonomous systems. These identities may not sit in HR systems or follow traditional joiner, mover, leaver processes, but they still hold access to business-critical applications, sensitive data, and production environments.
One identity leader at a Fortune 100 enterprise put it simply:
"Five years ago, my biggest concern was making sure the right people had the right access. Now I'm asking how many AI agents exist in my environment, what they're connected to, and who is responsible for them. The challenge isn't just governing people anymore."
That shift came up constantly. Identity leaders are not just asking who has access anymore. They are asking what has access, how that access was granted, whether it is still appropriate, and how it can be governed consistently.
This is why conversations around identity governance, non-human identities, and AI identity governance are becoming increasingly connected. Organizations do not want separate programs for every new identity type. They want one identity strategy that can scale across humans, non-human identities, and AI agents.
Last year, many AI governance conversations were still hypothetical. This year, they felt much more practical.
Security and identity teams are no longer only asking whether employees are using AI tools. They are asking how AI agents interact with enterprise systems, how access should be granted, how policies should be enforced, and who is accountable when an autonomous system takes action.
A security architect at a global financial services organization shared one of the clearest versions of the challenge:
"We know how to review employee access. We know how to review service accounts. But when an AI agent is connected to multiple systems and making decisions on behalf of users, the question becomes: who owns it, who reviews it, and who is accountable when something goes wrong?"
That is where AI governance becomes an identity governance issue. The challenge is not simply whether AI is safe. The challenge is whether organizations have the visibility, policy controls, and accountability needed to govern AI-driven access, and the AI access control tools required to do so.
As organizations move from AI experimentation to production deployments, the conversation is increasingly shifting from innovation to governance.
Across sessions, roundtables, and customer conversations, four questions surfaced repeatedly:
These are fundamentally identity governance questions, which is why AI governance and identity security are becoming increasingly intertwined.
Model Context Protocol, or MCP, came up in more conversations than many people expected.
That is not because identity leaders suddenly became focused on protocols for the sake of protocols. It is because MCP represents a much larger shift in how AI agents connect to enterprise systems. As organizations begin using MCP-connected applications and AI-driven workflows, they need to understand what agents can access, what actions they can take, and how those actions are governed.
One identity architect at a global technology company told us:
"MCP came up in more conversations than I expected. Organizations are excited about the possibilities, but they're also asking the same questions we ask about every new identity surface: who has access, what can it do, and how do we control it?"
That is exactly the conversation identity teams should be having.
MCP creates enormous potential for AI adoption, but it also introduces new governance requirements. If an AI agent can connect to business applications, retrieve data, invoke tools, and take action, then organizations need visibility and control over that activity. They need to know what the agent is doing before it becomes a blind spot.
This is why we announced the Linx MCP Gateway. The goal is to help organizations govern AI agents and MCP-connected systems with the same identity-first approach they already use for human and non-human identities.
Another major theme at Identiverse was the move from periodic governance to continuous governance.
Traditional identity governance has often been built around scheduled access reviews, quarterly certifications, and point-in-time reporting. Those processes still matter, especially for compliance. But identity leaders are increasingly looking for governance programs that can keep pace with how modern environments actually operate.
Access changes constantly. People move teams. Contractors leave. Service accounts accumulate privileges. AI agents connect to new systems. Permissions drift. Risk changes faster than quarterly review cycles can capture.
That is why so many conversations at Identiverse centered on real-time visibility, automated remediation, continuous controls, and AI-powered decision support.
Identity governance is no longer just about proving that a review happened. It is about knowing what changed, understanding why it matters, and taking action before risk accumulates.
This is also where Autopilot resonated with many of the identity leaders we spoke with. The idea of moving from manual identity work to autonomous identity security is becoming less futuristic and more necessary.
One of the most consistent takeaways from Identiverse was that identity teams do not want another silo.
They do not want one process for workforce identities, another for non-human identities, another for AI agents, and another for privileged access. They want a unified identity strategy that gives them visibility and control across the full identity landscape.z
One of the customers who joined us on stage summarized this well:
"We've spent years building governance processes for our workforce identities. Now we're applying those same principles to non-human identities and AI agents. The biggest lesson for us has been that these shouldn't be treated as separate problems. The more we can govern everything through a single identity strategy, the easier it becomes to maintain visibility, reduce risk, and operate efficiently."
That point captures where the market is headed.
The future of identity security is not about adding more disconnected tools. It is about building a governance model that can support every identity type across the enterprise. Humans, non-human identities, and AI agents all represent access paths into critical systems. They should be governed with the same level of visibility, accountability, and control.
For us, this is the larger story behind what we shared at Identiverse. MCP Gateway, AI Access Control, Autopilot, and our broader identity governance platform are all part of the same mission: helping organizations govern every identity from one place.
If there was one thing Identiverse 2026 made clear, it's that the future of identity security isn't something organizations need to prepare for years from now. It's already here.
AI agents, MCP-connected systems, non-human identities, real-time governance, and autonomous workflows are no longer emerging concepts. They're actively changing how organizations think about access, risk, and identity governance today. The challenge for identity leaders is no longer whether these technologies will become part of their environment. It's how quickly they can build the visibility, controls, and governance frameworks needed to manage them.
That's why so many of the conversations we had at Identiverse ultimately pointed back to identity. Whether the topic was AI governance, MCP security, user access reviews, non-human identities, or compliance, the underlying challenge was the same: understanding who or what has access, what they can do, and how that access should be governed.
At Linx, that's exactly the problem we're focused on solving. From modern identity governance and AI-powered access reviews to AI Access Control, MCP Gateway, and Autopilot, we're helping organizations govern human, non-human, and AI identities through a single platform and a single identity strategy.
The future of identity security will belong to organizations that can unify governance across every identity type. Based on what we heard at Identiverse, that future is arriving faster than most people expected.
If you'd like to see how Linx is helping organizations tackle these challenges, schedule a demo with our team. We'd love to continue the conversation.
The biggest themes we heard were AI governance, non-human identity governance, MCP security, real-time identity governance, and the need for unified visibility across human, non-human, and AI identities.
AI is changing identity governance by introducing new identity types, including AI agents and autonomous workflows. These systems can access applications, retrieve data, invoke tools, and take action, which means they need the same visibility, policy enforcement, and accountability as other identities.
Model Context Protocol, or MCP, helps AI agents connect to tools and enterprise systems. From an identity security perspective, MCP matters because it creates new access paths that organizations need to govern, monitor, and control.
AI Access Control is the ability to govern what AI agents can access, what actions they can take, and how those actions are monitored and enforced. It extends identity governance principles to AI agents and autonomous systems.
Agentic identity governance refers to the governance of AI agents as part of the broader identity landscape. It focuses on visibility, ownership, access control, policy enforcement, and auditability for AI-driven identities.
Organizations can govern AI agents by inventorying where agents exist, understanding what systems they can access, enforcing least privilege, reviewing agent permissions regularly, monitoring activity, and applying policy controls through platforms like Linx MCP Gateway and AI Access Control.
AI agents have moved from pilots to production. They are no longer summarizing documents or drafting emails — they are reading records, writing data, querying databases, and calling APIs inside the systems your business runs on. The Model Context Protocol (MCP) is the most popular way to connect them to those systems, and an MCP gateway is the control plane that sits in between.
But here's what most security teams discover after deploying one: a gateway alone doesn't provide you with governance. It handles authentication and enforces rules. What it doesn't answer are the identity questions that actually keep CISOs up at night — who is this agent acting on behalf of, what should it be allowed to do, and what did it actually do? Those are identity problems. And most MCP gateways weren't built to solve them.
An MCP gateway is a control plane that sits between AI clients — Claude, Cursor, ChatGPT, internal agent frameworks — and the MCP servers those clients connect to. Every tool call an agent makes passes through it. The gateway's job is to enforce who can reach what, inspect traffic in both directions, log activity, and route requests to the right upstream system.
Think of it as the equivalent of an API gateway, but purpose-built for the MCP protocol. Where a generic API gateway understands HTTP methods and endpoints, an MCP gateway understands tool calls, resource requests, and the context in which agents invoke them. That protocol-level awareness is what separates a real gateway from a proxy with some auth bolted on.
For enterprise security teams, an MCP gateway is the foundational infrastructure layer for governing AI agent activity — but it is the starting point, not the finish line.
MCP has become the dominant integration layer for connecting AI agents to enterprise data and tools. It is supported by Anthropic, OpenAI, Google, and Microsoft, and as of early 2026, the official MCP registry lists thousands of registered servers, with tens of thousands more available through community directories. Gartner predicts that 40% of enterprise applications will be integrated with task-specific AI agents by the end of 2026, up from less than 5% in 2025.
That scale creates a new attack surface. Agents don't browse — they act. An agent connected to your Salesforce, GitHub, and Jira instances through MCP isn't reading information for a human to evaluate. It is making decisions, executing tool calls, and producing effects in your production systems. The blast radius of a misconfigured or compromised agent is no longer theoretical.
The access controls enterprises rely on today were built for a different threat model: human-initiated, session-based access, where a person logs in, does something, and logs out. Agents don't work that way. They operate at machine speed, autonomously, chaining multiple tool calls across multiple systems in a single session — and they don't appear in the downstream application logs your security team relies on.
When an agent calls a tool through MCP, that action doesn't surface in Salesforce's audit log. It doesn't appear in your SIEM. It isn't captured by your DLP. The audit trail simply doesn't exist without an inline enforcement point. According to McKinsey's 2026 AI Trust Maturity Survey of approximately 500 organizations, nearly two-thirds cite security and risk concerns as the top barrier to fully scaling agentic AI — outranking regulatory uncertainty and technical limitations combined. The NSA's AI Security Center reinforced that signal in May 2026, publishing formal guidance on MCP deployments that identified authentication failures and trust boundary vulnerabilities as active, structural risks in enterprise AI stacks.
The gap isn't theoretical. It is the default state for most organizations deploying MCP today.
Many organizations deploying an MCP gateway configure it at the server level: this role can reach this MCP server, that role cannot. It's a reasonable starting point. It is not sufficient.
A single MCP server can expose dozens of tools with entirely different risk profiles. The Stripe MCP server exposes balance retrieval, charge creation, refund processing, and customer record access in the same package. A finance analyst with read-only responsibilities should be able to query balances. She should not be able to initiate a refund. An engineer troubleshooting an integration should see neither.
Server-level AI access control can't express that distinction. Without tool-level policy enforcement mapped to roles, teams, and personas, organizations face a binary choice: block AI adoption entirely, or accept ungoverned access at a scope far broader than any individual's actual job requires.
The common mistake is treating MCP governance as an authentication problem. OAuth 2.1, OIDC, SSO integration — these verify that the agent is who it claims to be. They say nothing about what it should be allowed to do in this specific context, for this specific task, invoked by this specific person.
Real MCP governance requires authorization at granular scope: not just which server, but which tools within that server, which actions within those tools, and which data those actions can touch. And it requires that authorization to be enforced in real time, before the action executes, not logged after the fact when the damage is done.
Here is where most MCP gateways stop, and where the real governance problem begins. A gateway that inspects tool calls but has no view into the identity behind them is enforcing policy on an entity it doesn't understand.
Agents are not users. They are not service accounts. They are a unique type of identity — acting on behalf of humans, operating under machine credentials, with permissions that frequently exceed those of the person who invoked them. Most IAM programs have no framework for that. There is no provisioning workflow, no access review cadence, no deprovisioning trigger when the employee behind the agent leaves or changes roles.
The questions no standalone MCP gateway can answer are the ones identity security posture management (ISPM) was built for:
Without answers to those questions, MCP governance is incomplete regardless of how well the gateway is configured - the human context is an integral part of the equation.
Governance that actually closes these gaps requires connecting the MCP layer to your broader identity program. Here is what that looks like in practice.
Linx is the identity governance platform already running across your humans and non-human identities. The MCP Gateway extends that same program — same access profiles, same access reviews, same JML — to AI agents. Not a new silo. The IGA you already run, reaching one layer deeper.
Access policy should specify which tools within each MCP server a given role, team, or persona can invoke — and which actions within those tools are permitted. An agent operating under a read-only finance persona should be able to call retrieve_balance. It should not be able to call create_charge. That distinction needs to be enforced by policy at the gateway layer, mapped to the same access profiles that govern human identities.
AI governance done right means the same access profile model governing your humans and NHIs extends to agents — one policy framework, not three across your environment.
Every tool call should be inspected and approved or blocked before it runs. This sounds obvious. Most deployments don't do it. Logging after the fact tells you what happened; it doesn't prevent the harm. Inline, real-time enforcement at machine speed is what governance actually requires when agents are taking actions faster than any human can review them.
Every approved and denied tool call should be captured, timestamped, and tied back to the specific human identity, non-human identity, or agent that initiated it. Not a generic service account. Not an agent ID with no owner. A complete chain of attribution that connects the action to the person behind it.
Identity intelligence that spans human and machine identities makes this possible — and makes it investigable when something goes wrong.
Agents should be provisioned, reviewed, and deprovisioned with the same rigor as human access. Identity lifecycle management that covers agents means access reviews include agent permissions alongside human ones, and offboarding a person also terminates the agent access they owned.
For high-sensitivity operations, JIT access for agents — scoped, time-limited permissions minted at task execution time rather than standing access — significantly reduces blast radius when an agent is compromised or misdirected.
A gateway is the enforcement point. An IGA program is the context that makes enforcement accurate. Linx has both built in - not a gateway bolted onto identity, but identity governance that reaches the gateway layer.
Regulatory pressure is arriving. The EU AI Act's rules for high-risk AI systems begin enforcement in August 2026, making audit-grade records a hard requirement for any agent touching credit, employment, healthcare, or critical infrastructure data. The NSA's May 2026 guidance elevated MCP security from a best practice to a formal design consideration for any organization running agents against sensitive systems. Gartner separately flagged that 25% of enterprise GenAI applications will experience at least five minor security incidents per year by 2028, in part because MCP was built for interoperability first and security second.
Organizations that treat MCP governance as an identity problem — not just a network or protocol problem — will be significantly better positioned to meet these requirements. The gateway is the enforcement point. Identity is the context that makes enforcement accurate.
Linx MCP Gateway sits inline between AI clients and the enterprise applications they connect to, enforcing tool-level policy in real time, logging every action with full attribution, and extending the same identity governance framework that covers your human and non-human identities directly to your agents. One platform to manage all policies across your entire identity landscape, rather than a separate tool trying to govern AI in isolation.
Ready to see it in action? Get a demo and see how Linx closes the identity gap in your MCP governance program.
An MCP gateway is a control plane that sits between AI clients and the MCP servers they connect to, enforcing authentication, access policy, and audit logging for every tool call that passes through. It gives enterprise security teams a centralized point to govern what AI agents can reach, what actions they can take, and a complete record of what they did.
An MCP gateway is purpose-built for the Model Context Protocol, meaning it understands tool calls, resource requests, and the agentic context in which they occur — not just HTTP methods and endpoints. Generic API gateways can proxy MCP traffic, but they lack the protocol-level awareness needed to enforce tool-level access policies or attribute actions to the human identity behind an agent.
Enterprise MCP gateways typically implement OAuth 2.1 with PKCE for the client-facing layer, integrated with your existing identity provider via OIDC or SAML for SSO. On the upstream side, a gateway brokers credentials on behalf of users — storing them server-side and exchanging them per tool call — so the AI client never holds raw credentials for downstream systems.
Without an MCP gateway, agents connect directly to MCP servers with no centralized enforcement point, creating credential sprawl, no audit trail, and no ability to block unauthorized tool invocations before they execute. Actions taken through MCP don't surface in downstream application logs, meaning security teams have zero visibility into what agents are doing inside business-critical systems.
MCP gateway governance is an extension of IAM into the agentic layer. Every agent is a non-human identity that needs to be provisioned, governed with least-privilege access, reviewed periodically, and deprovisioned when its owner leaves. An MCP gateway that isn't connected to your IAM program can enforce who reaches what, but it cannot answer who authorized this agent, whether its access is still appropriate, or what happens to its credentials when an employee is offboarded.
Enterprises should prioritize tool-level access control over server-level allow/block, inline real-time enforcement before actions execute, full audit logging with human identity attribution, and integration with their existing identity provider and access profiles. Gateways that operate in isolation from the broader IAM program create a separate governance silo — the strongest posture extends the same policy logic governing humans and non-human identities directly to agents.
AI access control is the practice of defining and enforcing what AI agents are permitted to do within enterprise systems — not just which systems they can reach, but which specific tools, actions, and data they can interact with. Effective AI access control operates at the tool level, maps to role-based access profiles, and enforces policy in real time before agent actions execute.
AI access control tools are platforms that govern what AI agents and AI-driven systems are authorized to access across your environment. They cover discovery (finding every agent, including shadow deployments), AI identity governance (enforcing least privilege and just-in-time access for non-human identities), inline enforcement (blocking unauthorized actions as they happen), and monitoring (tracking what agents do with the access they hold).
Traditional access control governs human-initiated, session-based access to resources. AI access control must govern machine-speed, autonomous, multi-step tool invocations made by agents that act on behalf of humans but under their own credentials. This requires enforcement at a finer granularity — individual tool calls rather than application logins — and attribution logic that connects agent actions back to the human identity behind them.
AI governance in enterprise security is the set of policies, controls, and processes that organizations use to ensure AI systems operate within defined boundaries, with appropriate oversight and accountability. For agentic AI, this includes inventorying AI agents as identities, enforcing least-privilege access, maintaining auditable records of agent activity, and integrating agent lifecycle management into existing identity and security programs.
Implementing AI governance for agents starts with treating each agent as a first-class identity: discover and inventory all agents in your environment, define access policies at the tool level mapped to roles and personas, enforce those policies inline at the MCP gateway layer, and connect agent lifecycle — provisioning, access review, and deprovisioning — to your existing identity governance program. Audit logging with full human identity attribution is non-negotiable for regulated environments.

Over the past year, several important developments have emerged across the security industry.
Researchers have demonstrated how AI can accelerate vulnerability discovery and exploit development. Security teams have uncovered new ways to manipulate AI agents through prompt injection and tool abuse. Governments have begun restricting access to advanced AI models due to national security concerns.
At first glance, these may seem like separate stories. In reality, they are all pointing to the same shift.
AI is no longer simply a tool employees use. It is becoming an active participant in enterprise environments. AI agents can access systems, retrieve information, invoke actions, and interact with sensitive data. In many cases, they can do so with a level of speed and autonomy that exceeds traditional software systems.
Most discussions around AI security focus on models, prompts, and productivity. The more important story may be what AI is teaching us about identity. As organizations deploy AI agents, MCP-connected applications, and autonomous workflows, they are introducing a new class of identities into their environments. These identities require the same visibility, accountability, and governance as human and non-human identities.
One of the most significant security shifts happening today has very little to do with AI-generated content or productivity gains. It is about speed.
Historically, organizations could rely on a window of time between vulnerability disclosure and widespread exploitation. Security teams could assess risk, prioritize remediation, deploy patches, and respond before attackers operationalize newly discovered weaknesses.
That assumption is becoming increasingly difficult to defend.
Research from Anthropic's Project Mythos demonstrated how advanced AI systems can assist in vulnerability discovery and exploit chain development at a scale previously impossible for human researchers alone. At the same time, organizations continue to face record volumes of disclosed vulnerabilities, making it increasingly difficult to distinguish critical risks from background noise.
The implication is not necessarily that AI is creating more vulnerabilities. It is that AI is dramatically reducing the effort required to find them.
This is creating a new reality for defenders. The challenge is no longer finding vulnerabilities. The challenge is fixing them before attackers can weaponize them. Security leaders are increasingly facing an environment where vulnerabilities are discovered, analyzed, and exploited faster than traditional remediation cycles can keep pace.
As AI continues to reduce the cost and complexity of vulnerability discovery, the balance between offense and defense begins to shift. Attackers require less expertise, less time, and fewer resources to identify opportunities. Defenders, meanwhile, are being asked to move faster than ever before.
That alone would be enough to reshape security priorities. However, it is only half of the story.
While AI is accelerating vulnerability discovery, organizations are simultaneously introducing entirely new forms of access into their environments.
The most interesting AI security incidents emerging today are not necessarily about the models themselves. They are about what happens when those models are connected to systems, applications, and data.
Microsoft's research into AI agent security has highlighted a growing class of risks, including prompt injection, credential abuse, unauthorized tool usage, and unintended actions triggered through manipulated inputs. Projects such as OpenClaw have further demonstrated how AI agents can be influenced through seemingly legitimate interactions and then use their existing permissions in ways their operators never intended.
These examples all point to the same issue.
The issue is not that the AI became malicious.
The issue is that the AI already had access.
For decades, organizations have invested heavily in security awareness programs designed to reduce human risk. Employees are taught how to recognize phishing attempts, avoid suspicious links, and identify social engineering tactics designed to manipulate behavior. Those programs are built around the assumption that humans can learn from mistakes and adapt their actions.
AI agents do not operate under the same assumptions.
An AI agent may have access to business applications, customer data, development environments, internal documentation, or financial systems. It may be capable of retrieving information, invoking tools, updating records, or executing workflows. When an attacker successfully manipulates that agent, they are often not breaking into a system. They are convincing a trusted identity to use the permissions it already possesses.
This is what makes AI agents fundamentally different from traditional software. They are increasingly acting on behalf of users, making decisions, and interacting with systems using permissions granted by the organization itself.
At some point, the conversation stops being about AI and starts becoming about identity.
The challenge organizations face today is not that identity governance is broken.
It is that the identity landscape has changed.
Most identity programs were designed around identities that were relatively easy to understand and manage. Employees have managers. Contractors have sponsors. Service accounts have owners. Access requests follow established workflows, and periodic reviews help ensure permissions remain appropriate over time.
AI agents challenge many of those assumptions.
Who owns an autonomous agent operating across multiple systems? Who reviews its permissions? How do organizations determine whether an agent should retain access six months after it was deployed? Who is accountable when it performs an action nobody anticipated?
These are fundamentally identity governance questions.
Historically, identity governance evolved from managing human identities to managing non-human identities. Service accounts, API keys, machine identities, and workloads all required organizations to expand governance beyond people.
AI agents represent the next stage of that evolution.
Unlike traditional applications, AI agents can operate with varying degrees of autonomy. They can access multiple systems, make decisions, invoke tools, and interact with sensitive data in ways that are difficult to predict in advance. In many organizations, those capabilities are being deployed faster than governance processes can adapt.
The result is not a technology problem as much as a governance problem.
Organizations need answers to fundamental questions:
Without those answers, AI becomes another source of identity sprawl.
If the incidents we have seen over the last year have anything in common, it is this:
The problem was not the model. The problem was the access.
The AI agent already had permission. The workflow already had credentials. The system already had the ability to act.
As organizations deploy more AI agents through MCP and similar frameworks, visibility into those permissions becomes critical. Security teams need to understand what agents can access, what tools they can invoke, what actions they can perform, and whether those actions align with organizational policy.
This is where AI access control begins to emerge as an important security discipline.
At its core, AI access control is about answering the same questions identity teams have asked for years: Who has access? What can they access? Why do they have that access? And is that access still appropriate? The difference is that those questions now apply to AI agents and autonomous systems as well.
Just as identity governance introduced oversight for human and non-human identities, organizations are beginning to apply those same principles to AI agents: visibility, ownership, least privilege, policy enforcement, access reviews, and auditability.
MCP governance plays an important role in this evolution. As AI agents become increasingly connected to enterprise systems through MCP servers and similar architectures, organizations need control points that allow them to understand and govern agent behavior. Without those controls, organizations risk creating highly privileged identities that operate with little visibility or oversight.
The future of AI security is increasingly identity-centric.
One of the biggest mistakes organizations can make is treating AI governance as a completely separate discipline.
In practice, AI agents are simply the newest category of identity.
Whether organizations refer to it as AI identity governance, agent governance, agentic identity governance, or AI access control, the underlying challenge is the same: AI agents are becoming participants in enterprise systems and must be governed accordingly.
Human users, service accounts, machine identities, API keys, and AI agents all represent access paths into critical systems and sensitive data. Creating separate governance programs for each introduces complexity, inconsistency, and blind spots. Instead, organizations should focus on a unified approach to identity governance that gives security teams visibility and control across every identity type.
That is why we introduced Linx AI Access Control.
AI Access Control extends identity governance to AI agents, MCP-connected systems, and autonomous workflows. Rather than treating AI governance as a separate security discipline, Linx helps organizations apply the same visibility, ownership, least privilege, access reviews, and policy enforcement they already use to govern human and non-human identities.
As AI agents become increasingly embedded within enterprise environments, organizations need a way to understand what those agents can access, who approved that access, how it is being used, and when it should be revoked. AI Access Control was built to help answer those questions.
As part of this approach, the Linx MCP Gateway provides organizations with a governance layer for AI agents and MCP-connected systems. It gives security teams visibility into agent activity and the ability to apply identity governance principles to emerging AI workflows before they become blind spots.
But the larger philosophy matters more than any individual product announcement. Organizations should not need separate governance programs for humans, non-human identities, and AI. They need one identity strategy that encompasses all three.
The same principles that govern employee access should govern agent access: visibility, ownership, least privilege, accountability, and continuous monitoring. The technology may be changing, but the principles of identity governance remain the same.
As AI becomes more deeply embedded within enterprise environments, identity teams have an opportunity to apply decades of governance experience to this new category of identities. The organizations that succeed will not view AI governance as a separate problem. They will treat it as part of their broader identity security strategy.
The AI security challenge is not simply that AI is helping attackers move faster.
It is that organizations are simultaneously creating thousands of new identities with access to critical systems, applications, and sensitive data.
The stories making headlines today, whether they involve accelerated vulnerability discovery, AI agent manipulation, model restrictions, or emerging governance concerns, are all pointing in the same direction.
AI is becoming part of the identity landscape.
Identity security has always been about controlling access. As AI becomes a participant in enterprise workflows rather than simply a tool, that mission remains the same.
The organizations that succeed will not be the ones that deploy AI the fastest.
They will be the ones who govern it best.
If you're looking to govern AI agents, MCP-connected systems, and every identity across your environment, schedule a demo with Linx to see AI Access Control and the Linx MCP Gateway in action.
Over the past few months, we have spoken with many security and IT leaders who are in the same position: their organizations are deploying Claude broadly across teams, but they have no idea who actually has access to it, what level of privilege those users hold, or what's happening with the API keys their developers have created. They're governing other application in their stack with rigor, but treating Claude as an exception.
That disconnect has always bothered us. Not only because Claude is unique, but because the same identity logic that protects every other application should apply here as well.
When Anthropic launched the Claude Compliance API, we ceased that opportunity. We're genuinely proud to be one of the integration partners building on it. Anthropic is setting the bar for what responsible enterprise AI deployment looks like, and the Compliance API is a direct expression of that: giving security and IT teams the programmatic access they need to govern Claude the same way they govern everything else that matters. Building on that foundation is something we are excited about.
Here's what we built.
Setting it up is simple. Follow the step-by-step integration guide and connect in just 60 seconds. Linx begins pulling data automatically.
Once connected, Claude shows up in Linx as a fully governed application, the same way Salesforce, Okta, GitHub, or any other app in your estate does. From that point forward, everything Linx does for your other applications, it now does for Claude.
The first thing security teams want to know is: who has access, and what can they do? With this integration, Linx gives you a complete view of every account provisioned in Claude, the roles assigned to each user, and the groups they belong to.
You can easily surface administrative roles and identify who holds elevated privileges, and drill into the specific permissions attached to each role. For compliance and least-privilege reviews, this alone is a significant step forward.
The AI-powered access certifications take the heavy lifting off identity and compliance teams, meaning faster turnaround, fewer errors, and a smoother process end to end.
The new integration allows you to easily review and certify access in Claude, using Linx’s AI-powered access review campaigns. The campaign surfaces every user and their entitlement type, along with AI context and recommendations on whether that access should be approved or denied, powered by Anthropic's own models.
So, you're combining Linx's identity governance context with Claude's intelligence to make faster, smarter access decisions. The reviewer doesn't have to make every call from scratch. They have a recommendation in front of them and the data to act on it.
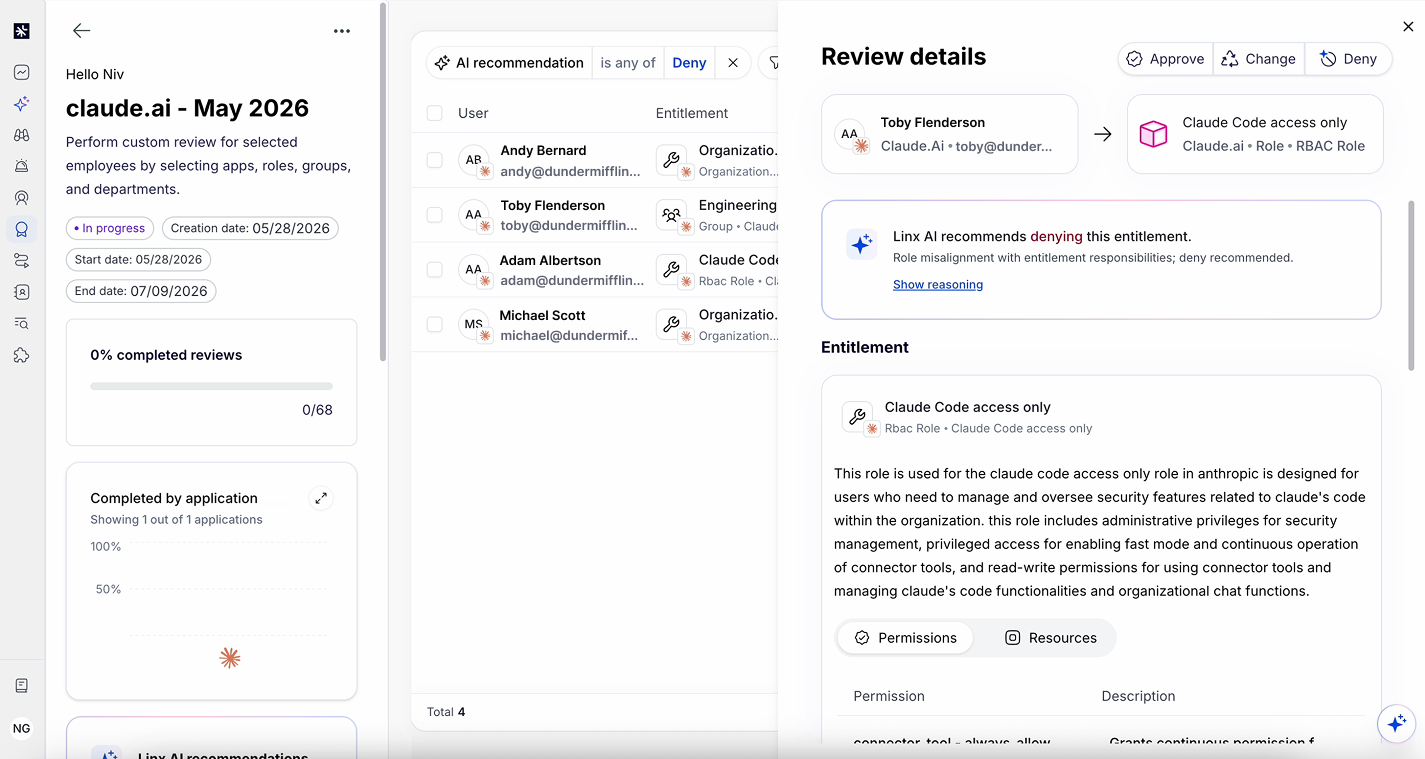
For teams running quarterly or annual access reviews, this changes the economics of the process considerably. What used to require manual triage across hundreds of accounts can now move in a fraction of the time.
One of the less visible but high-stakes risks in any AI deployment is unmanaged API keys. Developers create them, projects get deprecated, people leave the company, and the keys keep existing. Then something goes wrong.
Linx allows identity teams to closely monitor API keys created within Claude: when it was created, associated metadata, and enough context for a security team to evaluate whether it should still exist.
This is the kind of visibility that used to require a manual audit. Now it's continuous.
Finally, with this integration Linx provides the tools for real governance over projects and shared resources within Claude, with an access graph for each project that shows exactly how access is provisioned.
You see which roles exist, which users hold them, and how access flows through the system. For organizations with multiple teams working across different Claude projects, this provides the resource-level clarity that broad account views can't.
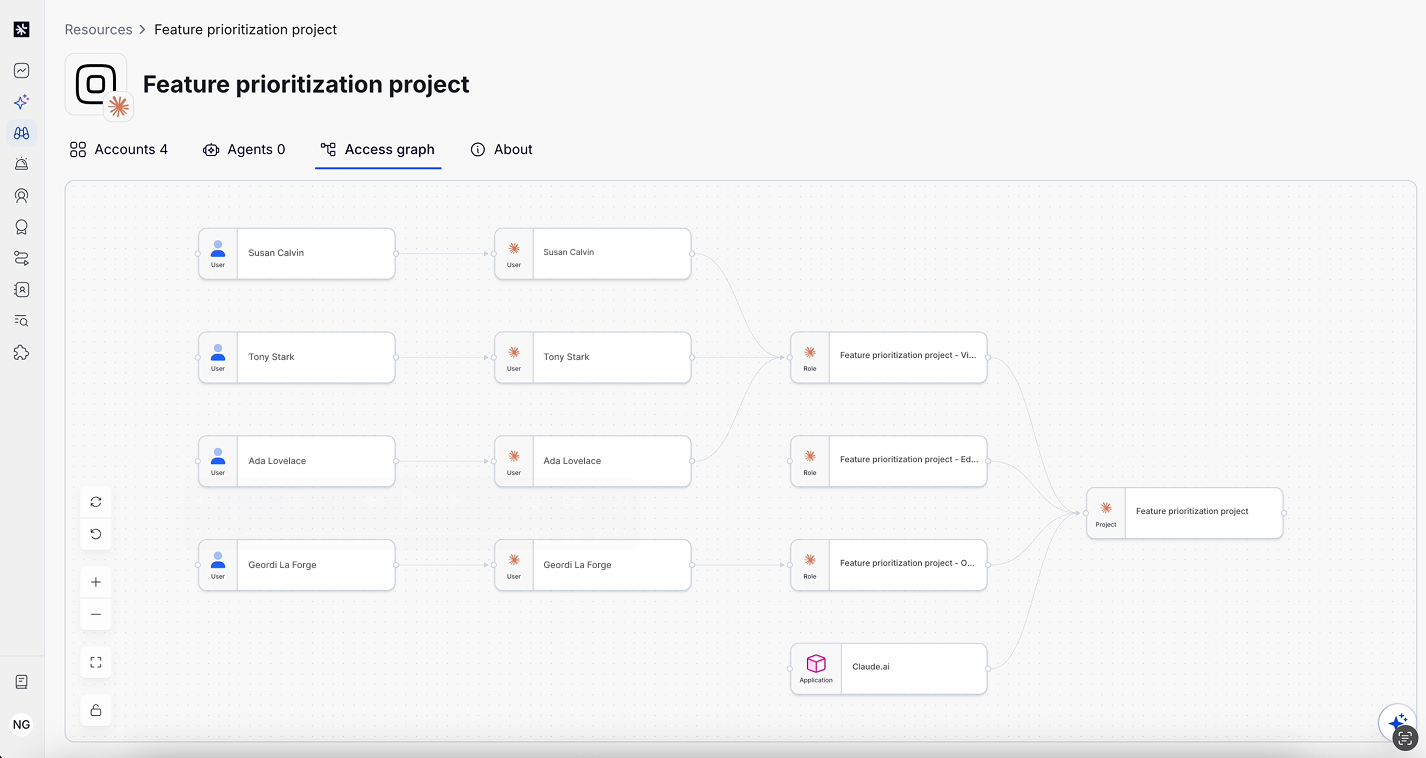
Security teams have spent years building strong identity governance programs: access reviews, offboarding workflows, least-privilege enforcement, audit trails. Claude is a critical app, and should be governed as such. With this integration, it is.
What makes this feel right to us as product builders is that we didn't create a separate Claude governance tool. We extended the identity fabric that our customers already rely on. Claude is governed in Linx as part of a whole, not as an exception. This means it benefits from everything Linx already does, and security teams don't have to learn a new workflow or platform to govern it.
We're proud to of this integration and to be shaping the future of AI security and governance. Being part of the ecosystem that makes Claude governable at scale is something the Linx team doesn't take lightly.
If you’re new to Linx, schedule a demo to experience truly unified identity governance.

MCP changed how AI agents interact with enterprise systems. By creating a standardized way for AI platforms to connect to applications, databases, and business tools, it dramatically lowered the barrier between AI and enterprise systems.
It also created a governance gap most organizations are not prepared for.
As AI agents gain access to business-critical applications, security teams have no reliable way to inspect actions, enforce policy, or establish accountability before those actions occur. Existing access controls were built for humans. They were not built for agents operating autonomously at machine speed across multiple systems.
Today, we're introducing Linx AI Access Control, a real-time enforcement layer that gives organizations visibility and control over every action taken through MCP.
Most enterprise access controls were designed around a fairly simple model. A user authenticates, receives permissions, performs actions within an application, and those actions are captured in logs that security teams can review later. The process is familiar, and while it isn't perfect, it creates a chain of accountability.
MCP changes that model.
When an AI agent receives a request, it doesn't operate inside a single application. It can invoke multiple tools across multiple systems, make decisions dynamically, and execute actions in seconds. A single prompt might trigger activity across Salesforce, Jira, GitHub, Snowflake, and several internal applications before a human ever sees the result.
The challenge is that traditional access controls cannot inspect activity at the point where those decisions are being made. Application logs can tell you that something happened. They cannot reliably tell you which agent initiated the action, which user was behind it, whether the activity aligned with policy, or whether it should have been allowed in the first place.
Without an enforcement layer sitting between the AI platform and the target application, that context simply doesn't exist.
This is quickly becoming one of the biggest barriers to enterprise AI adoption. According to McKinsey's State of AI Trust in 2026 report, nearly two-thirds of organizations cite security and risk concerns as the primary obstacle to scaling agentic AI initiatives.
Consider a simple example. An organization grants an AI agent read access to Salesforce so it can retrieve customer information. Later, that same agent is prompted to perform actions outside its intended purpose. Who evaluates the request? Who determines whether the action complies with policy? Who records what happened?
For most organizations today, the answer is nobody.
As we spoke with customers exploring AI adoption, we kept hearing the same concern.
Organizations understood how to govern people. They understood how to govern service accounts and non-human identities. It’s not perfect, and implementation is hard, but the principles are there. What they didn't understand was how to govern agents.
The problem wasn't a lack of visibility into MCP servers. The problem was a lack of visibility into what agents were actually doing once they got there.
That's why we built Linx AI Access Control.
The MCP gateway creates a dedicated enforcement point between AI platforms and the enterprise systems they access. Every MCP tool call passes through that control point before execution, creating a place where requests can be inspected, policy can be evaluated, and activity can be recorded before actions reach downstream systems.
One of the first design decisions we made was to focus on tool-level governance rather than server-level governance. Connecting to an MCP server is one thing. Determining what an agent can actually do once it's connected is something entirely different. Linx allows organizations to define which specific read, write, and administrative tools an agent can invoke, with policies mapped directly to Linx Access Profiles and governed by role, team, department, or persona.
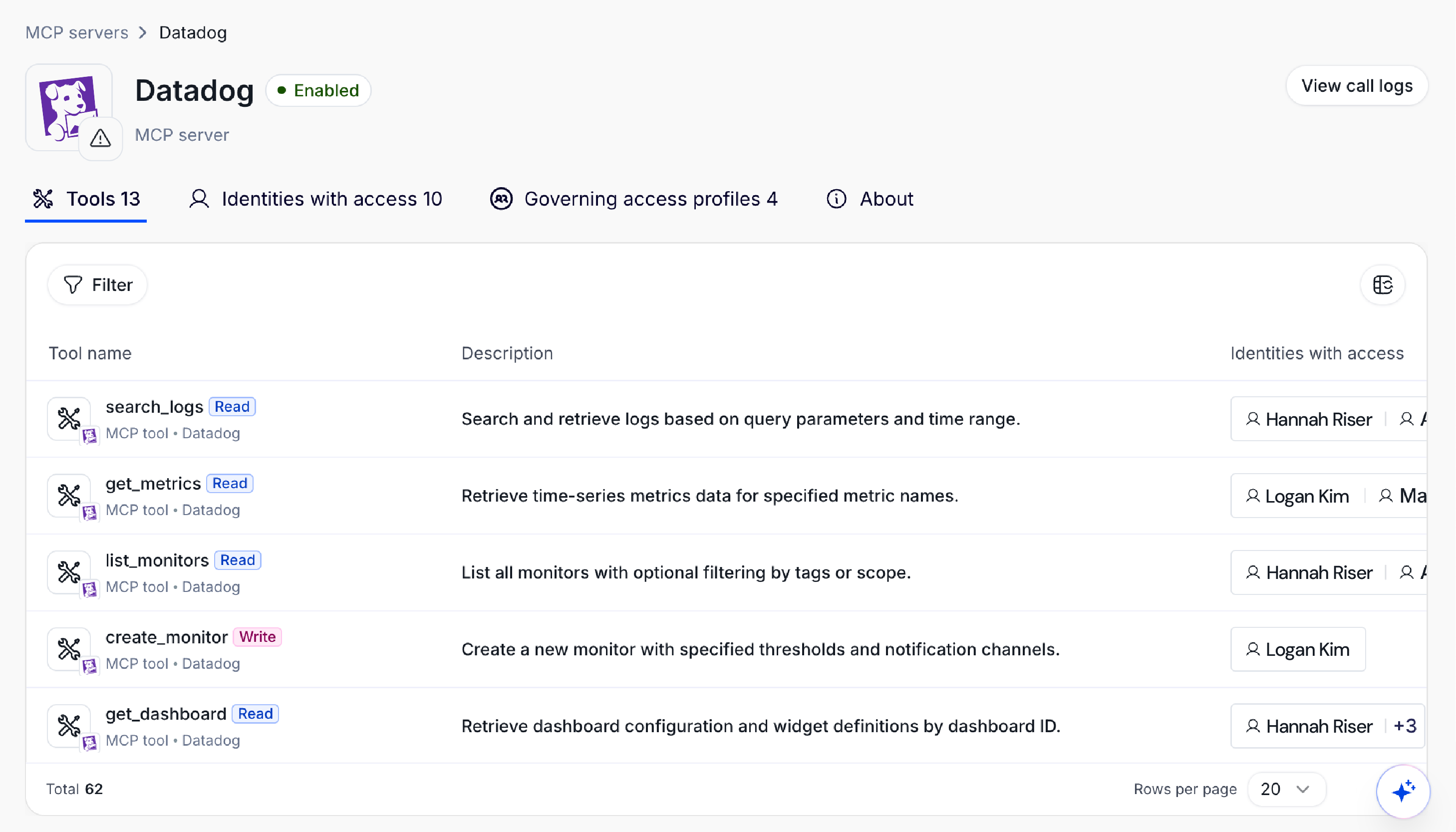
The gateway also performs policy evaluation in real time. Every request is inspected before execution and evaluated against organizational policy. Approved actions proceed. Violations are blocked before they reach the target application. The goal isn't to investigate risky behavior after it occurs. The goal is to prevent it from occurring in the first place.
Just as importantly, every approved and denied action is captured, timestamped, and attributable. Security teams gain a complete record of activity, including the identity behind the request, the tool being invoked, the action attempted, and the outcome. For the first time, organizations have an investigable record of what agents actually did, not simply what downstream systems recorded.
Most MCP governance solutions evaluate requests in isolation. They can see the agent making the request, but they lack the broader identity context required to make accurate policy decisions.
That context matters more than most organizations realize.
When a policy decision is made, Linx can evaluate the human behind the request, the non-human identity the agent is operating as, the access profile associated with that activity, and the specific action being attempted. Rather than looking at a single request in isolation, Linx evaluates the entire identity chain behind it.
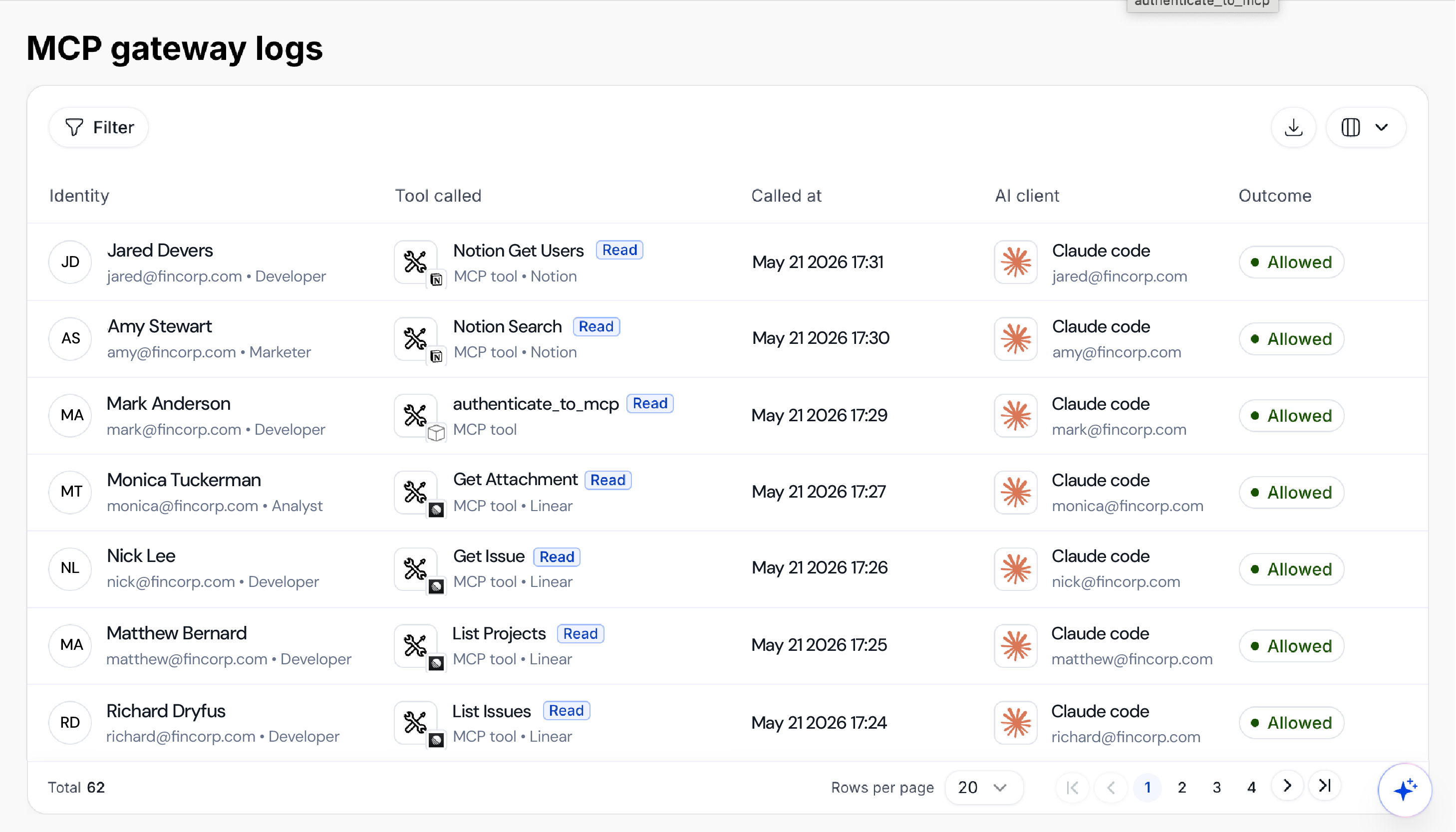
This is what allows enforcement to be precise rather than blunt. Without that context, organizations are often forced into a familiar tradeoff. Either permissions become so restrictive that productivity suffers, or access becomes so broad that risk increases.
Because AI Access Control is built directly into the Linx identity governance platform, the same access profile logic already used to govern human and non-human identities extends naturally to AI agents. Organizations don't need a separate governance model for agents. They can extend the one they already trust.
As AI adoption increases rapidly, we believe AI identity governance should not just keep up, but stay ahead.
We view the MCP Gateway as the core foundation of a broader AI governance strategy, providing real-time enforcement of granular, context driven, policy. We believe it must be coupled with comprehensive agent coverage and the full suite of governance capabilities. That is the only way to treat your agents as the first-class identities they are, and the only path to responsible AI acceleration.
That's why we’re so excited about building a unified, humans and agents, governance platform.
If you want to see Linx AI Access Control in action, join us for an in-person demonstration during Identiverse (June 15-17). To see Linx AI Access Control virtually, schedule a demo with our team to see it live.



.png)